Introducing Pub/Sub and employing Kafka with Python using the confluent-kafka library – Understanding Event-Driven Architecture
Introducing Pub/Sub and employing Kafka with Python using the confluent-kafka library
Before we get into what the modern Pub/Sub model is, let’s go into a bit of detail about the technology that made this field possible: Apache Kafka, the third most famous Kafka after Franz and Kafka on the Shore. Originally designed for use in LinkedIn (a great website), it was made open source in early 2011. The concept behind it was pretty simple: there is a log of information and events that any number of systems can consume, and data can be published to the log for consumption by these systems. Sound simple enough? Well, it is now, but it took some thinking to come up with it. But this is the system that is responsible for most modern data infrastructure that we see today. Have you ever gotten a notification on your phone? It is because of this library. Have you ever made a contactless payment with your phone or credit card? Chances are, Kafka’s in there. Ever gotten a notification for a YouTube video? Definitely Kafka.
In most cases where raw unadulterated Kafka is used, the distributor of information is called the producer and the receiver of said information is called the consumer. In most modern nomenclature, as well as with most cloud services, they are instead called the publisher and the subscriber.
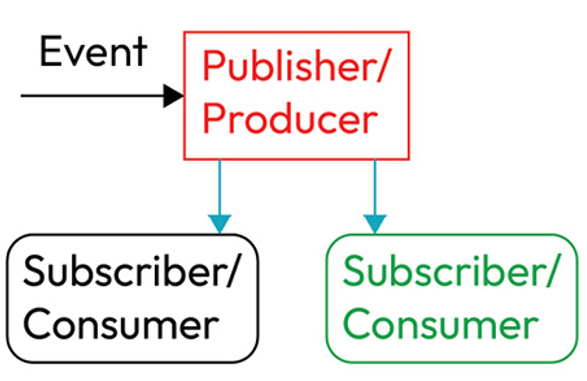
Figure 8.1 – Events processing with the Pub/Sub model
Before we dive into the use of Kafka and Python in DevOps, we must first look at a sample usage of Kafka with Python using the confluent-kafka library:
- Let’s first install the library using pip:
pip install confluent-kafka
2. Now, as mentioned before, Kafka is divided between a producer and a consumer. So, let’s first write a piece of code that creates a producer:
from confluent_kafka import Producer
import socket
conf = {‘bootstrap.servers’: ‘<host_name>:9092’,
‘client.id’: socket.gethostname()}
producer = Producer(conf)
3. This code will configure a producer. Replace host_name with the name of an Apache Kafka cluster (online or locally). Next, we need to use the configured producer to send some data. Let’s look at that code now:
producer.produce(topic, key=”key”, value=”value”)
Here, topic is the location where the publisher or producer will distribute their content for it to be consumed. The key and the value elements are the keys and values that will be distributed by the producer.
4. Let’s now add some code for a consumer that will pick up messages sent by the producer:
from confluent_kafka import Consumer
conf = {‘bootstrap.servers’: ‘<host_name>:9092’,
‘group.id’: ‘<group_id_here>’,
‘auto.offset.reset’: ‘smallest’}
consumer = Consumer(conf)
The consumer now listens on the same host that the producer sends messages on. So, when the producer produces a message, the consumer can consume it. When a consumer is subscribed to a topic, that consumer is constantly listening to the message at certain intervals. Once the message arrives, it will begin the process of interpreting the message and sending it to the appropriate location.
5. To have the consumer continually listen to the producer for messages, we can place it in a loop:
while True:
msg = consumer.poll(timeout=1.0)
if msg is None: continue
break
#If msg is not None, it will break the loop and the message will be processed
This is simply understanding the way that these Pub/Sub mechanisms work. In application, it is much easier since some sort of mechanism to perform this will already be provided for you. This is, however, a good way to learn how to make custom Pub/Sub structures if you want to, and to just understand Pub/Sub structures in general.
Here’s what the key takeaway from this should be: this is how the world works. Exactly like this. Most of the things that come to your phone come from this. Most of the things that go out of your phone go to this. It’s also true on a more fundamental level as well, as we will see in the next section.